
✅ 핵심 키워드
논리 데이터 모델링
- 데이터베이스 설계 프로세스의 기초 설계 단계로 비즈니스 정보의 구조와 규칙을 명확하게 표현할 수 있는 기법이다.
물리 데이터 모델링
- 관계 데이터 모델링으로도 불리며 논리적 데이터 모델을 DBMS의 특성, 기능, 성능 등을 고려하여 데이터베이스의 물리적인 구조(Schema)를 작성해 나가는 기법이다.
정규화(Nomalization)
- 관계형 데이터 모델에서 데이터의 중복성을 제거하여 이상 현상을 방지하고, 데이터의 일관성과 정확성을 유지하기 위해 무손실 분해하는 과정이다.
데이터 마이닝(Data Mining)
- 대규모로 저장된 데이터 안에서 체계적이고 자동적으로 통계적 규칙이나 패턴을 찾아내는 기술이다.
✅ 6. 논리 데이터 저장소 확인
💡 데이터 모델
- 현실 세계의 데이터를 추상화하여 형식화한 것이다.
- 개체-관계(E-R) 모델과 관계형 데이터 모델에 대한 이해가 필요하다.
- 데이터베이스의 구조와 제약 조건을 정의한다.
💡 논리 데이터 모델 검증
- 데이터 모델이 요구사항을 충족시키는지를 검증하는 과정이다.
- 릴레이션 스키마, 함수적 종속성, 정규화 등의 논리 데이터 모델링에 대한 이해가 필요하다.
- 데이터 모델의 일관성, 중복 제거, 무결성 등을 확인한다.
💡 기출
[단답형] 2020년 2회
다음은 데이터 모델링 절차이다. 절차에 맞도록 보기에서 찾아 채우시오.
- 요구 사항 분석 → (개념적 데이터 모델) → (논리적 데이터 모델) → (물리적 데이터 모델)
[단답형] 2021년 1회
다음은 DB 설계 절차에 관한 설명이다. 다음 빈칸에 들어갈 알맞은 용어를 쓰시오.
- (개념적 설계)은/는 현실 세계에 대한 인식을 추상적, 개념적으로 표현하여 개념적 구조를 도출하는 과정으로 주요 산출물에는 E-R 다이어그램이 있다.
- (논리적 설계)은/는 목표 DBMS에 맞는 스키마 설계, 트랜잭션 인터페이스를 설계하는 정규화 과정을 수행한다.
- (물리적 설계)은/는 특정 DBMS의 특성 및 성능을 고려하여 데이터베이스 저장 구조로 변환하는 과정으로 결과로 나오는 명세서는 테이블 정의서 등이 있다.
[해설]
요개논물: 요구 사항 분석 → 개념적 데이터 모델 → 논리적 데이터 모델 → 물리적 데이터 모델
- 요구 사항 분석
- 정보 시스템 구축에 필요한 요구 사항을 파악하고 분석한다.
- 사용자, 업무 프로세스, 데이터 등에 대한 요구 사항을 수집하고 분석한다.
- 개념적 데이터 모델
- 요구 사항 분석을 기반으로 업무적인 개념을 표현하는 추상적인 데이터 모델링이 이루어진다.
- 실제 데이터베이스의 구조와는 독립적인 업무적인 개념을 모델링한다.
- 논리적 데이터 모델
- 개념적 데이터 모델을 상세화하여 실제 데이터베이스에서 사용될 수 있는 구조로 변환한다.
- 업무적인 개념을 데이터베이스 객체로 변환하고, 관계형 데이터 모델링 기법을 이용하여 테이블 구조와 제약 조건 등을 정의한다.
- 물리적 데이터 모델
- 논리적 데이터 모델을 구현하기 위해 실제 데이터베이스 시스템에서 사용될 구조로 변환한다.
- 데이터베이스 관리 시스템에 맞춰 데이터 타입, 인덱스, 파티션, 저장소 등 물리적인 요소들을 추가하여 최적화한다.
- 구현: SQL문을 실행하여 데이터베이스를 실제로 생성한다.
[단답형] 2021년 1회
다음 빈칸에 들어갈 데이터 모델의 구성요소를 쓰시오.
- 데이터 모델에서는 (연산)을/를 이용하여 실제 데이터를 처리하는 작업에 대한 명세를 나타내는데 논리 데이터 모델에서는 (구조)을/를 어떻게 나타낼 것인지 표현한다. 제약 조건은 데이터 무결성 유지를 위한 DB의 보편적 방법으로 릴레이션의 특정 칼럼에 설정하는 제약을 의미하며, 개체 무결성과 참조 무결성 등이 있다.
[해설]
- 연산(Operation): 데이터베이스에 저장된 실제 데이터를 처리하는 작업에 대한 명세이다.
- 구조(Structure): 데이터베이스에 논리적으로 표현될 대상으로서의 개체 타입과 개체 타입들 간의 관계이다.
- 제약 조건(Constraint): 데이터 무결성을 유지하기 위한 DB의 보편적 방법이다.
[단답형] 2021년 1회
주어진 테이블의 Cardinality, Degree를 구하시오.

- Cardinality: 5
- Degree: 4
[해설]
- 카디널리티(Cardinality): 관계형 데이터 모델에서, 릴레이션 간의 관계의 수를 나타낸다.
- 차수(Degree): 관계형 데이터 모델에서, 릴레이션에 포함된 속성(attribute)의 수를 나타낸다.
[단답형] 2021년 2회
다음은 부분 함수 종속성을 제거하여 완전 함수 종속을 만족하는 (2 정규형)이다. 괄호 안에 알맞은 정규형을 쓰시오.
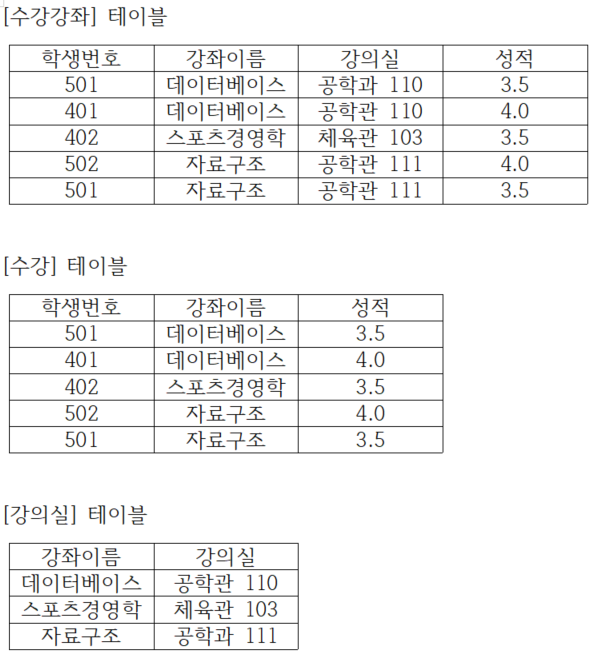
[해설]
데이터베이스 정규화 단계: 원부이 결다조
- 제1정규화(1NF): 릴레이션의 모든 도메인이 원자 값(Atomic Value)만으로 구성되도록 분해한다.
- 제2정규화(2NF): 부분 함수 종속을 제거하기 위해 릴레이션을 분해한다.
- 제3정규화(3NF): 이행적 함수 종속을 제거하기 위해 릴레이션을 분해한다.
- BCNF: 결정자 함수 종속을 제거하기 위해 릴레이션을 분해한다.
- 제4정규화(4NF): 다치 종속을 제거하기 위해 릴레이션을 분해한다.
- 제5정규화(5NF): 조인 종속을 제거하기 위해 릴레이션을 분해한다.
[단답형] 2021년 1회
정규화된 엔터티, 속성, 관계에 대해 성능 향상과 개발 운영의 단순화를 위해 중복, 통합, 분리 등을 수행하는 데이터 모델링의 기법을 무엇이라고 하는지 쓰시오.
- 반 정규화(De-Normalization)
[약술형] 2020년 1회
비 정규화(De-Normalization)의 개념을 쓰시오.
- 정규화된 엔터티, 속성, 관계에 대해 성능 향상과 개발 운영의 단순화를 위해 중복, 통합, 분리 등을 수행하는 데이터 모델링의 기법이다.
[해설]
반 정규화(De-Normalization)
- 성능 향상과 개발 운영의 단순화를 위해 중복, 통합, 분리 등을 수행한다.
- 데이터 모델링에서 중복된 데이터를 추가하거나 릴레이션을 합치는 등의 작업을 수행하여 성능을 향상한다.
- 중복 데이터와 일관성 유지, 무결성 등을 고려하고 신중한 판단이 필요하다.
[단답형] 2020년 4회
이상 현상의 종류 3가지를 쓰시오.
- 삽입 이상, 삭제 이상, 갱신 이상
[약술형] 2022년 1회
이상 현상 중 삭제 이상에 대해 서술하시오.
- 정보 삭제 시 원치 않는 다른 정보가 같이 삭제되는 이상 현상이다.
[해설]
이상 현상: 삽삭갱
- 삽입 이상(Insertion Anomaly), I(릴레이션): 정보 저장 시 해당 정보의 불필요한 세부 정보를 입력해야 하는 이상 현상이다.
- 삭제 이상(Deletion Anomaly), D(릴레이션): 정보 삭제 시 원치 않는 다른 정보가 같이 삭제되는 이상 현상이다.
- 갱신 이상(Update Anomaly), U(릴레이션): 중복 데이터 중에서 특정 부분만 수정되어 중복된 값이 모순을 일으키는 이상 현상이다.
[단답형] 2022년 2회
다음은 관계 데이터 모델과 관련된 설명이다. 괄호 안에 공통적으로 들어갈 용어를 쓰시오.
- (관계 해석)은/는 관계 데이터베이스에 대한 비절차적 언어이며, 수학의 Predicate Calculus에 기반을 두고 있다. Codd 박사에 의하여 제시되었으며, 튜플 (관계 해석), 도메인 (관계 해석)이/가 있다.
[해설]
대절해비: 관계 대수는 절차적 언어이고 관계 해석은 비절차적 언어이다.
- 관계 대수(Relational Algebra): 릴레이션과 관련된 질의를 처리하는 데 사용되는 언어로, 튜플에 대한 기본적인 집합 연산을 수행하는 대수 체계이다.
- 관계 해석(Relational Calculus): 릴레이션에 대한 논리적 기술을 사용하여 릴레이션에서 원하는 데이터를 찾는 방법을 기술하는 언어로, 질의어를 이용하여 데이터에 대한 질문을 하며 이에 대한 응답을 제공한다.
[단답형] 2022년 3회
올바른 관계 대수 기호를 쓰시오.
- (∪): 합집합
- (-): 차집합
- (×): 카티션 프로덕트
- (π): 프로젝트
- (⋈): 조인
[단답형] 2022년 2회
다음 [EMPLOYEE] 테이블에 대하여 πTTL(EMPLOYEE) 연산을 수행하면 나타나는 결과를 채워 넣으시오.
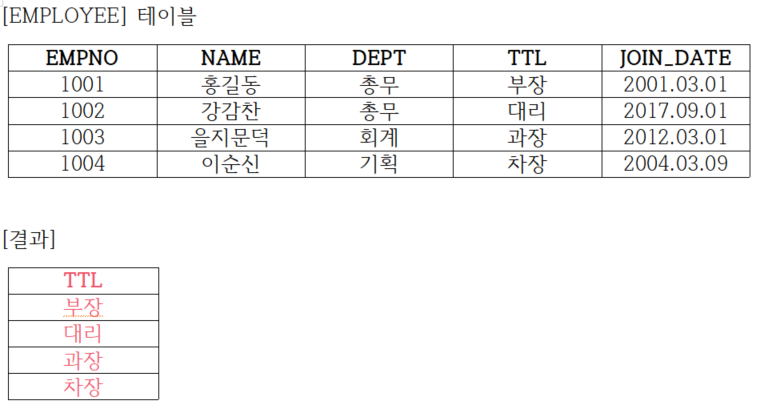
[단답형] 2020년 3회
릴레이션 A, B가 있을 때 릴레이션 B 조건에 맞는 것들만 릴레이션 A에서 튜플을 꺼내 프로젝션 하는 관계대수는 무엇인가?
- 디비전(Division), ÷
[해설]
- 일반 집합 연산자
- 합집합(Union, ∪): 두 개 이상의 릴레이션을 합쳐서 중복을 제거한 새로운 릴레이션을 만든다.
- 교집합(Intersection, ∩): 두 개 이상의 릴레이션에서 공통된 튜플을 선택하여 새로운 릴레이션을 만든다.
- 차집합(Difference, -): 두 개의 릴레이션에서 첫 번째 릴레이션에만 있는 튜플들을 선택하여 새로운 릴레이션을 만든다.
- 카디션 프로덕트(Cartesian Product, ×): 두 개의 릴레이션을 조합하여 새로운 릴레이션을 만든다.
- 순수 관계 연산자
- 셀렉션(Selection, σ): 릴레이션에서 조건에 맞는 튜플들을 선택한다.
- 프로젝션(Projection, π): 릴레이션에서 특정 칼럼(열)을 선택하여 새로운 릴레이션을 만든다.
- 조인(Join, ⋈): 두 개 이상의 릴레이션을 연결하여 새로운 릴레이션을 만든다.
- 디비전(Division, ÷): 릴레이션 간의 나눗셈 연산으로, A 릴레이션에서 B 릴레이션의 모든 튜플을 만족하는 A의 튜플들만을 선택한다.
[단답형] 2022년 3회
다음은 E-R 다이어그램이다. 괄호 안에 들어갈 구성요소를 E-R 다이어그램의 보기에서 고르시오.
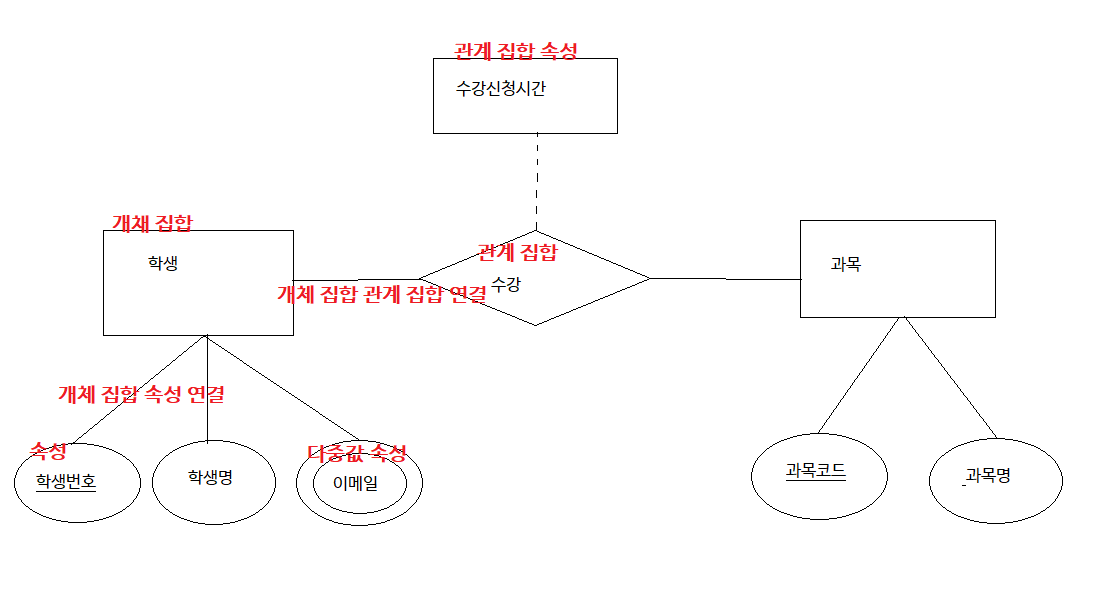
- (속성, 원): 개체 집합의 단일 속성을 나타낸다.
- (관계 집합 속성): 관계 집합의 속성을 나타낸다.
- (개체 집합 속성 연결, 실선): 개체 집합과 속성을 이어준다.
- (개체 집합 관계 집합 연결, 실선) : 개체 집합과 관계 집합을 이어준다.
- (관계 집합, 마름모): 관계 집합을 나타낸다.
[해설]
- 엔터티(Entity), 사각형: 현실 세계에서 독립적으로 존재하며 유일하게 식별 가능한 대상을 나타내는 기호이다.
- 속성(Attribute), 타원형: 엔터티에 대한 특성을 나타내며, 특정 값의 범위를 가진다.
- 식별자(Identifier), 밑줄: 엔터티 내에서 각각의 튜플을 유일하게 식별할 수 있는 속성이다.
- 관계(Relationship), 마름모: 엔터티 간의 관계를 나타내며, 관계의 정의와 특성을 명시한다.
- 기본키(Primary Key), 밑줄이 있는 타원형: 엔터티의 식별자 중에서 유일성과 최소성을 만족하는 속성 또는 속성 조합이다.
- 외래키(Foreign Key), 이중 선과 밑줄: 다른 엔터티의 기본키를 참조하는 속성으로, 두 엔터티 간의 관계를 나타낸다.
- 카디널리티(Cardinality), 선과 화살표: 엔터티 간의 관계에서 한 엔터티의 인스턴스가 다른 엔터티와 얼마나 많은 관계를 가지는지 나타내는 기호이다.
- 모델링 구성요소, 다이아몬드, 원, 선: 특정 업무 분야에서 필요한 정보를 추출하기 위해 모델링하는 과정에서 사용하는 부가적인 기호이다.
[단답형] 2022년 2회
다음 설명 중 괄호 안에 들어갈 단어를 보기에서 찾아 쓰시오. (Determinant, Constraint, Transitive, Full, Depenent, Partial, Consisitency)
- 관계 데이터베이스에서 X 속성에 의해 Y 속성이 유일하게 결정되면 Functional Dependency가 성립한다고 하며 X→Y라고 표현한다.
- 학년은 학번에 의해 결정되므로 (Full) Functional Dependency가 성립하는 반면, 성적은 {학번, 과목번호}에 의해 (Full) Functional Dependency가 성립하지만 학년은 (Partial) Functional Dependency가 성립한다.
- 속성 X, Y, Z에 대하여 X→Y이고 Y→Z이면, X와 Z는 (Transitive) Functional Dependency가 성립한다.
[해설]
- 결정자(Determinant): 함수적 종속성에서 한 릴레이션에서 다른 속성들을 유일하게 결정할 수 있는 속성 또는 속성의 집합이다.
- 제약 조건(Constraint): 데이터베이스에서 데이터의 무결성과 일관성을 유지하기 위해 적용되는 규칙이다.
- 이행적 종속성(Transitive Dependency): 함수적 종속성에서 A가 B를 결정하고, B가 C를 결정하는 경우 A는 C를 간접적으로 결정하게 되어 A → C의 함수적 종속성을 가진다.
- 완전 종속성(Full Dependency): 어떤 속성이 기본키에 대해 함수적으로 종속된다.
- 종속성(Dependent): 함수적 종속성에서 결정자(Determinant)가 되는 속성이다.
- 부분적 종속성(Partial Dependency): 기본키의 일부 속성에만 종속된다.
- 일관성(Consistency): 데이터베이스의 무결성을 유지하기 위해 데이터베이스에서 저장되는 데이터의 일관성을 유지한다.
✅ 7. 물리 데이터 저장소 설계
💡 물리 데이터 모델 설계
- 정보처리에서 중요한 역할을 하며, 데이터베이스의 물리적인 구성을 결정한다.
- 데이터베이스의 크기, 성능, 보안 등을 고려하여 적절한 데이터 저장 방법과 인덱스를 결정한다.
- 데이터베이스의 효율적인 운영과 유지보수에 큰 영향을 미치므로 신중하게 진행한다.
💡 물리 데이터 저장소 구성
- 정보처리에서 데이터를 저장하고 처리하기 위한 하드웨어적인 구성이다.
- 저장할 데이터의 양, 접근 빈도, 처리 속도 등을 고려하여 디스크, 메모리, 캐시 등의 구성을 결정한다.
- 데이터 처리의 효율성과 안정성에 큰 영향을 미치므로 신중하게 계획되어야 한다.
💡 기출
[단답형] 2022년 1회
다음은 키에 대한 설명이다. 괄호 안에 들어갈 용어를 쓰시오.
- 슈퍼 키는 (유일성)의 속성을 갖는다.
- 후보 키는 (유일성)과/와 (최소성)의 속성을 갖는다.
[해설]
- 기본 키(Primary Key): 릴레이션에서 각 레코드를 식별하기 위해 선택된 유일한 키로, 중복되지 않고 null 값을 가질 수 없다.
- 대체 키(Alternate Key): 기본키와 마찬가지로 유일성을 보장하지만, 기본키로 적합하지 않은 경우 사용되는 키를 의미한다.
- 후보 키(Candidate Key): 릴레이션에서 기본키로 선택될 수 있는 가능성이 있는 키를 의미하며, 유일성과 최소성의 조건을 만족한다.
- 슈퍼 키(Super Key): 릴레이션에서 유일성을 보장하는 키로, 하나 이상의 속성을 포함하지만 최소성의 조건을 만족시키지 않는다.
- 외래 키(Foreign Key): 릴레이션 간의 참조 무결성을 유지하기 위해, 다른 릴레이션의 기본키를 참조하는 속성으로, 해당 속성 값은 참조하는 릴레이션의 기본키 값과 일치하거나 null 값이어야 한다.
✅ 8. 데이터베이스 기초 활용하기
💡 데이터베이스 종류
- 관계형 데이터베이스, 객체지향 데이터베이스, NoSQL 데이터베이스 등이 있다.
- 관계형 데이터베이스는 테이블 간의 관계를 중심으로 데이터를 구성하며, SQL을 사용하여 데이터를 관리한다.
- 객체지향 데이터베이스는 객체지향 프로그래밍과 유사한 방식으로 데이터를 구성하며, 자바나 C++ 등의 프로그래밍 언어를 사용하여 데이터를 관리한다.
💡 기출
[약술형] 2020년 1회
데이터 마이닝의 개념에 관해서 서술하시오.
- 대규모로 저장된 데이터 안에서 체계적이고 자동적으로 통계적 규칙이나 패턴을 찾아내는 기술이다.
[해설]
데이터 마이닝
- 대규모의 데이터에서 유용한 정보를 추출하고, 통계적 기법과 머신러닝 기술 등을 활용하여 특정 패턴이나 규칙을 찾아내는 기술이다.
- 데이터베이스나 데이터 웨어하우스 등에서 데이터를 분석하고 모델링하여 새로운 지식을 발견하고 의사결정에 활용한다.
- 비즈니스, 과학, 의료 등 다양한 분야에서 활용한다.
'기타 > 정보처리기사' 카테고리의 다른 글
| 정보처리기사 정처기 | 실기 7 SQL 응용 | 데이터베이스 기본, 응용 SQL 작성하기, SQL 활용 및 최적화 | 단원별 정리 (0) | 2023.03.08 |
|---|---|
| 정보처리기사 정처기 | 실기 6 프로그래밍 언어 활용 | C언어, 자바, 파이썬 | 단원별 정리 (1) | 2023.03.08 |
| 정보처리기사 정처기 | 실기 5 인터페이스 구현 | 인터페이스 설계 확인, 인터페이스 기능 구현, 인터페이스 구현 검증 | 단원별 정리 (0) | 2023.03.08 |
| 정보처리기사 정처기 | 실기 4 통합 구현 | 연계 메커니즘 구성, 내외부 연계 모듈 구현 | 단원별 정리 (0) | 2023.03.08 |
| 정보처리기사 정처기 | 실기 2 화면 설계 | UI 요구사항 확인, UI 설계 | 단원별 정리 (0) | 2023.03.08 |
| 정보처리기사 정처기 | 실기 1 요구사항 확인 | 소프트웨어 개발 방법론, 현행 시스템 분석, 요구사항 확인 | 단원별 정리 (0) | 2023.03.08 |
| 정보처리기사 정처기 | 필기 5과목 정보시스템 구축 관리 | 기출문제 정리본, 두문자 (0) | 2023.02.27 |
| 정보처리기사 정처기 | 필기 4과목 프로그래밍 언어 활용 | 기출문제 정리본, 두문자 (0) | 2023.02.27 |



